Ron Wilson The influence of Moore's Law has begun to weaken, but people's demand for performance has not weakened. For this reason, the entire industry seems to have embarked on the path to the development of multi-core processors and their larger counterparts, heterogeneous multi-core systems. This development is expected to dramatically change the software developer's environment, but few people in the industry are concerned about what software or system programmers should do. this is too scary! One thing is very clear is that the demand for high-performance computing will not quickly disappear, because the performance requirements of applications and systems have reached the limit of the computing power that current computer systems can provide, and urgently need to obtain higher calculations in the future. ability. If you need persuasive evidence, here are three examples of three different industries: ■? At the Linley conference's Internet of Things (IoT) industry conference last year, a case study outlined the design of a smartphone. In addition to the CPU, this watch also contains dozens of GPUs. In the telecommunications industry, with the advent of LTE-Advanced (most people call 4G or 4G+) wireless technologies, architects estimate that next-generation base stations will require approximately 500 cores to meet the specification's 1 millisecond delay. 5G may require higher. In the automotive industry, Edwin Olson, associate professor of computer science and engineering at the University of Michigan, warned that in order to meet the computational needs of advanced driver assistance systems (ADAS), the computing platform in the prototype was equipped with approximately 40 cores. It is expected that this will require heat dissipation for power supplies larger than 500 watts. Do not forget that this is still a mobile platform. These are traditional embedded environments, and we haven't even discussed data centers. The ITRS 2.0 roadmap indicates that it will take only two years to grow from 29 cores in 2017 to 48 cores per route. If you are working in software for the design industry, should you worry about it? Do you work in a new generation of parallel programming languages? Are you evaluating a change that you must learn new patterns like we do in client-server computing, object-oriented programming, or thread programming? At first these technologies were more complicated, but in the end we all achieved it. The question is what exactly we need to change. Is adapting this new multicore computing technology a process of learning new coding techniques? Do we have to use new languages ​​for design verification to show how we use all these cores? Are we studying how to fundamentally change the way system development? Operating system vendors need to take the lead in coping with this new multi-core world. They are convinced that simple additions to the programming models (threads and object models) that we are already familiar with are sufficient for application programmers and thus prevent a crisis. The operating system vendor Symmetric Multiprocessing (SMP) backfills the details of handling multiple cores, hiding the complexity involved in processing these architectures. This is what we think of today's programming industry that requires high performance computing (HPC). But this may not be the end. When the programming industry goes through one of these transformations, there always seems to be a large number of new languages. Do you remember Objective-C, the beginning of X-windows programming? Do you remember that hardware enthusiasts insisted that Verilog (similar to the C language hardware description language) or VHDL (similar to ADA's hardware description language, very popular with hardware designers) is the programming method of the future world? Of course, this is before MATLAB and its similar graphical programming languages ​​are considered to be the programming style of the future world. It seems like we are in the early stages of such transformation. Leading developers have embarked on some form of inherent parallelism, and it seems that some form of parallelism is coming. When you think of OpenCLTM or OpenVX, the automotive industry thinks of AutoSAR, and the HPC industry thinks of POSIX threads or MPI. The compiler industry has been studying this area for at least 10 years. But apart from the special cases where the code can be parallelized (as in pixel-level or image-level repetition), such as task-level parallelism (TLP), data-level parallelism, or pipeline-level parallelism (PLP), there is no breakthrough to provide. (C++)++. Maybe it will be achieved. However, unfortunately, everything is only ominous. What can you do? What should you do? To answer this question, we need to have a deeper understanding of the internals of multi-core systems. If you look at how most of today's systems are implemented, you will find that in a hardware server rack, each server card carries both CPU and GPU chips and is layered by an operating system that provides some type of SMP. If such a system can meet your immediate problems, it is awesome. However, keep in mind that these SMP systems have been built as shared memory systems and only for applications that can handle shared memory models. If you get performance that does not meet your needs, you will add more cores. Whether there is a good return on investment (ROI) for adding additional cores and whether you have provided data centers with unnecessary heating, little attention has been paid. As long as adding a kernel can solve the problem, no one cares about it. But if you use Linux as an SMP operating system, there are inherent problems that make performance predictions (ie, determining return on investment) difficult. There are five specific issues that must be understood or at least described. ■? Environment switching: Consider the environmental load/storage overhead; these situations may occur at unwanted/uncontrolled time points; ■The amount of payload data sent on the communication channel between cores ■? Interrupts the cycle in the real-time operating system ■Overhead is built into the inter-task communication application programming interface (API) for simplified programming ■? Multiple programs and daemons that run in the background and can move user threads or rearrange These are some unpleasant problems. Nobody talks about these problems. Everyone wants them to be eliminated when the system is debugged. But in order to be able to predict performance improvements and analyze the return on investment before having a complete system prototype, you must consider these facts. These complex problems already exist in SMP systems. But if you plan to explore truly heterogeneous computing, such as adding one or more DSPs to the architecture to speed up signal processing, or adding hard IPs for wireless applications (such as Fast Fourier Transform (FFT) cores or Viterbi decoders ), then a single operating system can not be achieved. Each core has its own operating system, core, or bare-metal environment. Managing all these different operating systems and the coding of each computing infrastructure is challenging. The third method that gets people’s attention is hyperscale, which uses one or more FPGA fabrics. There are two aspects that most often discuss the issue of using a pooled FPGA. One of these aspects is to improve specific network latency, where disk access is an important part of application execution time. For example, millions of database accesses to a relational database on a network-attached storage device. Add OS abstraction to the Network File System (NFS) and its associated unpredictability, which can affect your ability to predict calculation time. The second aspect includes machine learning or machine reasoning that leverages the trade-offs associated with floating-point and fixed-point methods in FPGAs. So far, we have understood this kind of computational requirements through top-down and bottom-up approaches, respectively. The top-down approach includes more and more popular multiple-valued mechanisms. The bottom-up approach includes several multi-core architectures provided by semiconductor vendors. In fact, this bottom-up approach forces programmers to find matching top-down approaches. Or, if you start with a bottom-up approach, system programmers often cannot easily bind parallel specifications to a multicore architecture while maintaining cross-architecture portability, which is often a key requirement. Regardless of the method used, the mapping process is cumbersome, with many manual operations and repetitions. For example, if you target Linux SMP, you must use the operating system task settings to write parallel code directly (for example, P threads). These codes can be ported up to other platforms that use the same operating system (and version). Given that most computing environments tend to use Linux, this is not a problem, but using this approach eliminates the possibility of using other operating systems that may appear or use the code on truly heterogeneous platforms. If system programmers program in the OpenCL language, they want vendors to be able to support platform-independent libraries in order to truly compare cross-architecture performance and portability. But usually, this is not the case. Even before we understand the bond between the top-down approach and the bottom-up approach, we have missed the basic first step and started to choose possible solutions. We lack clear criteria to measure the advantages of different implementations, so before we have a complete prototyping system to measure, we lack the tools for predicting advantages. Each question has its own preferred criteria for assessing its advantages. For example, system parameters such as cost, throughput, and delay may be obvious. But power consumption may not be. In wireless base stations that often use hundreds of cores, different solutions can achieve very different peak power consumption curves from 40% to 60%. This difference will definitely affect the type of power supply and the price that the network operator maintains. As mentioned above, the power consumption of the automotive multi-core ADAS during operation may be around 200 watts. If the system has multiple boards, this can cause thermal problems. But heat is mainly a function of average power, not peak power. Not only are system developers facing these prediction problems. Platform developers must also understand the impact of their architectural choices. From a bottom-up or architectural perspective, it is important to be able to quantify where each method has an advantage. We need to measure how the architecture of a particular solution enhances or reduces the need for specific problems. Implementation is a manifestation of behavior in architecture. Therefore, there are some issues that need to be considered when assessing the implementation of behavior on the architecture. Are you measuring the actual parameters of interest? Before the system exists, what should we do? Can you adjust the solution to optimize for the parameters of interest? During the design cycle, is it too late for you to obtain useful parameters, so that the system is no longer applicable? Can I optimize multiple parameters at the same time, or do you risk making the gradual approach an infinite return? Is there a way to consider the inherent limitations of the problem area? We see that, driven by physical entities, system developers are increasingly using symmetric architectures and now heterogeneous multicore architectures. These architectures in turn place new requirements on operating system vendors and are changing the way we capture software designs. However, our multi-core system modeling approach has not changed. We still predict the impact of task mapping, memory allocation, and coding decisions on the final system performance in the original way. These predictions not only need to understand simple speed standards, but also need to understand a wider range of attributes, including bandwidth, average power, and delays for specific subtasks. Our forecast needs to reflect what actually happens under the API level, and even if it should be hidden by application developers, operating system activity can greatly affect system behavior. As we are making decisions that affect the basic level of implementation (for example, what types of hardware perform tasks), we need to make accurate predictions early in the design process. In short, we need tools that support early behavioral code, not tools that support optimization modules. We need these tools to identify the factors that are critical to the final system performance but are not so obvious. These factors include not only the traditional code segment analysis, but also the transfer of data and control between tasks and between processors. Interface behavior, and important dynamic power behavior. These tools are emerging, but for the current generation of system design, it is time for them to appear.
Slide Switches
The Slide Switches is used to switch the circuit by turning the switch handle to turn the circuit on or off. It is different from our other serious switches, for example, Metal Switches, Automotive Switches, LED light Switches, Push button Switches, Micro Switches, The commonly used varieties of Miniature Slide Switches are single pole double position, single pole three position, double pole double position and bipolar three position. It is generally used for low voltage circuits, featuring flexible slider action, stable and reliable performance. Mainly used in a wide range of instruments, fax machines, audio equipment, medical equipment, beauty equipment, and other electronic products.
The Mini Slide Switches are divided into: low-current slide switches (right), and high-current slide switches (left). Small current slide switches are commonly used in electronic toys, digital communications. High current is generally used in electrical appliances, machinery, etc.
It can divided into 4 types modals, respectively are:
1. High-current sealed switch
Its rated current is as high as 5A, and it is sealed with epoxy resin. It is a large current sealed switch. It has a variety of terminal forms, contact materials are silver, gold, switching functions. Therefore, there are many types of subdivisions. Widely used in electrical appliances and machinery
2. Single sided snap-on surface mount type slide switch
The actuator is operated on the side and the pins are patch-type, so it is a unilateral spring-back surface mount type slide switch. Widely used in communications, digital audio and video
3.4P3T in-line slide switch
The contact form is 4P3T and the pin is in-line. It is 4P3T in-line slide switch. 4P3T determines that it has 8 pairs of pins. At the same time, there are two pairs of brackets that support, fix, and ground. Widely used in building automation, electronic products
4.Long actuator jacking type slide switch
Actuator 12mm, and located at the top of the switch, it is a long actuator jacking type slide switch. Widely used in digital audio and video, various instruments / instrumentation equipment
Slide Switches,Micro Slide Switch,2 Position Slide Switch,Momentary Slide Switch YESWITCH ELECTRONICS CO., LTD. , https://www.yeswitches.com
Many shapes and sizes of multi-core solutions 
Figure 1. Different parallel-valued mechanisms begin to appear. (Image provided by)
Isomorphic Kernel and SMP
The beginning of true heterogeneity 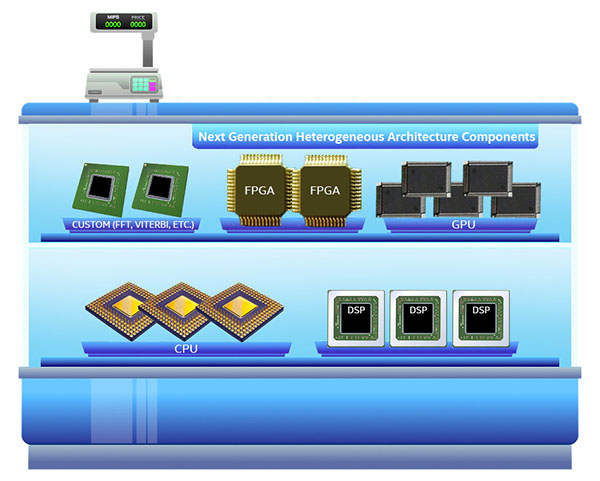
Figure 2. Rich choices for various computing needs. (Image provided by)
Top down and bottom up 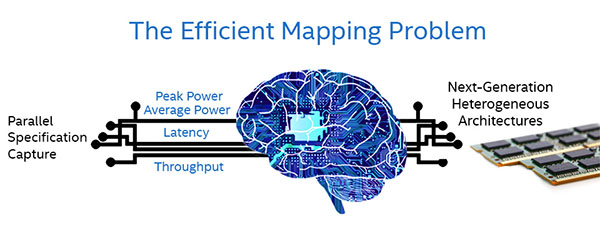
Figure 3. Efficient mapping is not simple! (Image provided by)
in conclusion

