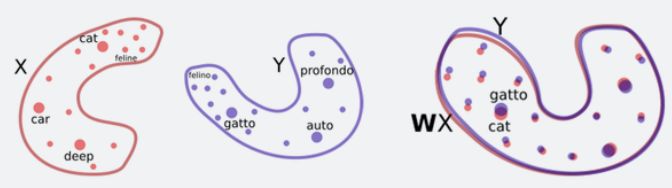
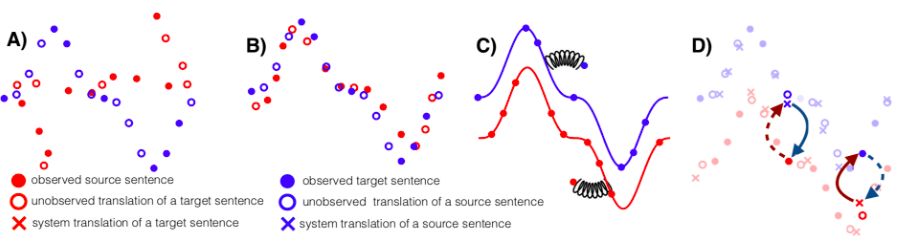
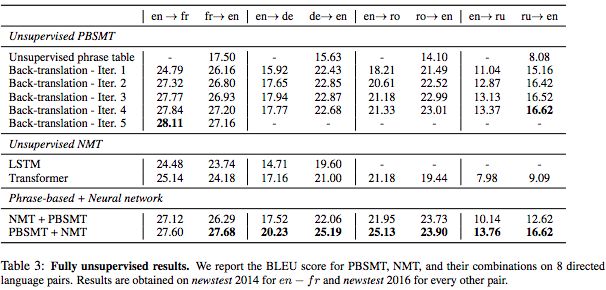
Facebook researchers have proposed a new unsupervised machine translation method, which has achieved an improvement of more than 10 points on the BLUE benchmark test. The researchers said that this unsupervised method is not only suitable for machine translation, but can also be extended to other fields, allowing the agent to use unlabeled data to complete tasks with little or no training data. This is a major breakthrough in machine translation and unsupervised learning. The implementation method itself is also very clever, and related papers have been accepted by EMNLP 2018. Automatic language translation is very important for Facebook, because Facebook has billions of users, and you can imagine the number of languages ​​that its platform carries and needs to be converted every day. Of course, with neural machine translation (NMT) technology, the speed and level of machine translation have been greatly improved. However, both traditional statistical machine translation and NMT require a lot of training data, such as Chinese-English, English-German, English-French and other language pairs. For languages ​​with less training data, such as Nepali, it is difficult to deal with. This is also one of the reasons for the strange religious prophecies in Google Translate, because the "Bible" is one of the most translated texts. Experts speculate that Google should use the "Bible" text to train Google's machine translation system. After the input, the machine desperately tries to "find out" the meaning from it, and then some sentences from the "Bible" will appear. The topic is far off. Come back to the problems that Facebook faces. As mentioned earlier, how to solve the problem of machine translation in small languages, that is, when there is no large amount of training data? Facebook researchers proposed a "MT model that does not require any translation resources", that is, "unsupervised translation", which they believe is the future development direction of machine translation. At the upcoming EMNLP 2018, Facebook researchers will present their results. The new method is a significant improvement over the previous state-of-the-art unsupervised methods, and its effect is equivalent to a supervised method trained with nearly 100,000 reference translations. Measured by BLEU, a commonly used benchmark for machine translation, Facebook’s new method has achieved an improvement of more than 10 points (an increase of 1 point on BLEU is already a pretty remarkable result). For machine translation, this is a very important finding, especially for small languages, some have very little training data, and some don’t even have training data. The unsupervised machine translation proposed by Facebook can initially solve this problem, such as in Urdu (Note: the national language of Pakistan, belongs to the Indo-Aryan branch of the Indo-Iranian family of the Indo-European language family; it is the global ranking of users. Automatic translation between the 20th language) and English-does not require any translated language pair. This new method opens the door for faster and more accurate translation of more languages. At the same time, the relevant technical principles may also be used in other machine learning and artificial intelligence applications. Translate word-to-word by rotating and aligning word embedding structure Facebook's method of unsupervised machine translation first is to let the system learn bilingual dictionaries and associate a word with multiple translations in other languages. For example, it is like letting the system learn that "Bug" as a noun means "bug", "computer loophole", and "bug". Facebook used the method they introduced in their previous paper "Word Translation Without Parallel Data" published in ICLR 2018, allowing the system to first learn word embeddings, that is, the vector representation of words, for each word in each language. Then, the system will train the word embedding to predict the words around the given word based on its context (for example, 5 words before and after the given word). Although word embedding is a very simple representation method, very interesting semantic structure can be obtained from it. For example, the word "kitty" (cat) is the closest to the word "cat", and the distance between the word "kitty" and "animal" is much smaller than it and "rocket" ( Rocket) the word distance. In other words, "kitty" rarely appears in the context of "rocket". You can simply rotate and align the two-dimensional word embeddings of the two languages ​​(X and Y), and then implement word translation through nearest neighbor search. In addition, words with similar meanings in different languages ​​have similar neighborhood structures because people all over the world live in the same physical environment. For example, the relationship between "cat" and "furry" (毛毛毛) in English is similar to their Spanish translations "gato" and "peludo", because the frequency of these words and their contexts are very similar . In view of these similarities, Facebook researchers have proposed a method for the system to learn to rotate the word embedding structure of one language through adversarial training and other methods, so as to match the word embedding structure of another language. With this information, they can infer a fairly accurate bilingual dictionary, without any already translated sentences, and can basically do word-by-word translation. By rotating and aligning the word embedding structure of different languages, a word-to-word translation is obtained Use unsupervised reverse translation technology to train sentence-to-sentence machine translation system When the word-by-word translation is realized, the next step is the translation of phrases and even sentences. Of course, the result of verbatim translation cannot be directly used in sentence translation. As a result, Facebook researchers used another method. They trained a monolingual language model to score the results given by the word-for-word translation system, so as to exclude sentences that did not conform to grammatical rules or have language problems as much as possible. This monolingual model is relatively easy to obtain, as long as there is a large number of monolingual data sets in a small language (such as Urdu). The English monolingual model is better constructed. By using the monolingual model to optimize the word-by-word translation model, a relatively primitive machine translation system is obtained. Although the translation results are not ideal, this system is already better than verbatim translation, and it can translate a large number of sentences from the source language (such as Urdu) to the target language (such as English). Next, Facebook researchers used these machine translation sentences (translated from Urdu to English) as ground truth for training machine translation from English to Urdu. This technique was first proposed by R. Sennrich et al. in ACL 2015 and is called "reverse translation". At that time, it used a semi-supervised learning method (with a large number of language pairs). This is the first time that reverse translation technology has been applied to a completely unsupervised system. It is undeniable that due to the translation errors of the first system (the original machine translation system from Urdu to English), the quality of the English sentences input as the training data is not high, so the Urdu output of the second reverse translation system The effect of Duyu translation can be imagined. However, with the Urdu monolingual model trained just now, you can use it to correct the Urdu translation output by the second reverse translation system, so as to continuously optimize, iterate, and gradually improve the second A reverse translation system. Three principles of unsupervised machine translation: word-to-word translation, language modeling and reverse translation In this work at Facebook, they identified three steps—word-by-word initialization, language modeling, and reverse translation—as important principles of unsupervised machine translation. With these principles, various models can be derived. The red dot represents the source language, the red circle represents the unobserved target language translation, the red cross represents the system’s translation to the target language; the blue dot represents the target language, the blue circle represents the unobserved source language translation, and the blue cross represents the system’s translation to the source. Language translation. A) Construction of word embedding models for two languages; B) Word-to-word translation by rotating aligned word embedding; C) Improving through monolingual model training; D) Reverse translation. Facebook researchers used it to build two different models to solve the goal of unsupervised machine translation. The first is an unsupervised neural model, which results in a smoother translation than verbatim translation, but it does not produce the quality translation that researchers want. However, the translation results of this unsupervised neural model can be used as training data for back translation. The translation results obtained using this method are equivalent to the effect of a supervised model trained with 100,000 language pairs. Next, Facebook researchers applied the above principles to another machine translation model based on classical counting statistics, called "phrase-based MT" (phrase-based MT). Generally speaking, these models perform better when there is less training data (that is, translated language pairs), and this is the first time they have been applied to unsupervised machine translation. The phrase-based machine translation system can derive correct words, but still cannot form fluent sentences. However, the results obtained by this method are also better than the most advanced unsupervised models before. Finally, they combined the two models to get a smooth and accurate translation model. The method is to start with a trained neural model and use the reverse translation sentence generated by the phrase-based model to train the neural model. Based on the empirical results, the researchers found that the last combination method significantly improved the accuracy of the previous unsupervised machine translation. On the BLEU benchmark test, the translation of English-French and English-German languages ​​improved by more than 10 points (English-French and English-German translations are also used For unsupervised learning and training, only the translated language pair is used for evaluation during the test). The researchers also tested languages ​​that are far apart in language (English-Russian), languages ​​that have fewer training resources (English-Romanian), and languages ​​that are far apart and have few training resources (English-Urdu) ) Translation. In all cases, the new method is a great improvement over other unsupervised methods, and sometimes even exceeds the results obtained by a translation system trained with a supervised learning method. Suitable for unsupervised learning in any field, allowing agents to perform rare tasks using unlabeled data Facebook researchers said that improving the BLEU test benchmark by more than 10 points is an exciting start, but what is even more exciting for them is the possibility that this approach opens up for future improvements. In the short term, this will definitely help us translate more languages ​​and improve the translation quality of languages ​​with less training data. However, the knowledge gained from this new method and basic principles can go far beyond the scope of machine translation. Facebook researchers believe that this research may be applied to unsupervised learning in any field, and allows agents to use unlabeled data to perform tasks that currently have only a few or no expert demonstrations. This work shows that the system can at least learn without supervision and build a coupled system in which each component is in a virtuous circle, continuously improving over time. Now, this project has been open sourced on Github, and the code can be obtained by visiting the following link: https://github.com/facebookresearch/UnsupervisedMT Related papers: https://arxiv.org/pdf/1804.07755.pdf The ONU in EPON adopts the mature technology Ethernet protocol, which can realize low-cost Ethernet layer 2 and layer 3 switching functions. This kind of ONU can provide shared high bandwidth for multiple end users through cascading. In the communication process, no protocol conversion is needed, and the transparent transmission of user data can be realized. ONU also supports other traditional TDM protocols without increasing the complexity of design and operation. Epon Onu 1ge 1fe 1pots,1GE 1FE 1POTS EPON ONU,Epon Voip Onu,Pots Port,Voice Port Shenzhen GL-COM Technology CO.,LTD. , https://www.szglcom.com


The OLT and all ONUs in EPON are managed by the network element management system, and the network element management system provides the operating interface with the core network of the service provider. The scope of network element management involves fault management, configuration management, billing management, performance management, and security management.
working principle:
1. Downstream data stream uses time division multiplexing (TDM) technology
During the transmission of the EPON signal, the downstream data is broadcast from the OLT to multiple ONUs. According to the IEEE802.3 protocol, the length of these data packets is variable, and the longest can reach 1518 bytes. Each data packet has its own destination address information, that is to say, the header of each packet indicates whether the data is for ONU1, ONU2 or ONUn. In addition, some packets can be sent to all ONUs, called broadcast packets, and some are sent to a special group of ONUs, called multicast packets. The data stream is divided into n independent signals after passing through the optical splitter, and each signal contains all specific data packets. When the ONU receives the data stream, each ONU extracts the data packets destined for itself according to the specific address information, and discards those data packets with different address information.
2. Upstream data flow uses time division multiple access (TDMA) technology
During the transmission of the EPON signal, the upstream data is sent from multiple ONUs to the OLT in a time division multiple access mode. Each ONU is assigned a transmission time slot. These time slots are synchronized. Therefore, when data packets are coupled to an optical fiber, different ONUs will not cause interference. For example, ONU1 transmits data packet 1 in the first time slot, ONU2 transmits data packet 2 in the second unoccupied time slot, and ONUn transmits data packet n in the nth unoccupied time slot, so that transmission conflicts can be avoided.