If you know a little bit about deep learning or have seen deep learning online courses, you must know the most basic multi-classification problems. Among them, the teacher will definitely tell you that the Softmax function should be added after the fully connected layer. If under normal circumstances (abnormal conditions refer to when there are too many categories) use the cross entropy function as the loss function, you will definitely get a let You are basically satisfied with the result. Moreover, many open source deep learning frameworks have directly written various loss functions (even the CrossEntropyLoss in Pytorch has already integrated the Softmax function), you don't have to worry about how to implement them, but you really understand why Do you want to do this? This short article will tell you: how Softmax converts the output of CNN into probability, and how cross entropy provides a measure for the optimization process. In order for readers to understand deeply, we will implement them one by one in Python. â–ŒSoftmax function The Softmax function receives a N-dimensional vector as input, and then converts the value of each dimension into a real number between (0, 1). Its formula is as follows: Just like its name, the Softmax function is a "soft" maximum value function. It does not directly take the maximum value of the output as the classification result, but also considers other relatively small types of output. To put it bluntly, Softmax can map the output of the fully connected layer into a probability distribution. The goal of our training is to let the samples belonging to the k-th class pass through Softmax, the greater the probability of the k-th class, the better. This makes the classification problem better explained by statistical methods. Using Python, we can implement the Softmax function like this: What we need to pay attention to is that the floating-point type in numpy has a numerical limit. For float64, its upper limit is In order to make the Softmax function more stable at the level of numerical calculation and avoid the situation of nan in its output, a very simple method is to perform a one-step normalization operation on the input vector, just multiply the numerator and denominator by a constant C, As shown in the following formula In theory, we can choose any value as Also using Python, the improved Softmax function can be written like this: â–ŒThe derivative inversion process of Softmax function From the above we have learned that the Softmax function can convert the output of the sample into a probability density function. Because of this good feature, we can add it to the last layer of the neural network, as the iteration process continues to deepen , Its most ideal output is the One-hot representation of the sample category. Let's take a closer look at how to calculate the gradient of the Softmax function (although you do not need to derive step by step with a deep learning framework, but in order to design new layers in the future, it is still very important to understand the principle of backpropagation) , To derive the parameters of Softmax: According to the quotient derivation rule, for . in in case in case So the derivative of the Softmax function is as follows: â–ŒCross entropy loss function Let's take a look at the loss function that really plays a role in model optimization-cross entropy loss function. The cross entropy function reflects the similarity between the probability distribution of the model output and the probability distribution of the real sample. Its definition is like this: In the classification problem, the cross entropy function has replaced the mean square error function in a large range. In other words, when the output is a probability distribution, the cross-entropy function can be used as a measure of ideal and reality. This is why it can be used as the loss function of a neural network activated by the Softmax function. Let's take a look at how the cross entropy function is implemented in Python: â–ŒThe derivation process of the cross entropy loss function As we said before, the Softmax function and the cross-entropy loss function are a good pair of brothers. We use the previous conclusion of deriving the softmax function derivative, and cooperate with the derivative of the cross-entropy function: Add the derivative of the Softmax function: y represents the one-hot encoding of the label, so As you can see, this result is really too simple, I have to admire the great gods who invented it! Finally, we convert it into code: â–ŒSummary It should be noted that, as I mentioned before, in many open source deep learning frameworks, the Softmax function is integrated into the so-called CrossEntropyLoss function. For example, Pytorch's documentation clearly tells readers that CrossEntropyLoss this loss function is a combination of Log-Softmax function and negative log-likelihood function (NLLoss), which means that when you use it, there is no need to use it in the fully connected layer. Add the Softmax function later. There are many articles that mention SoftmaxLoss. In fact, it is a combination of the Softmax function and the cross entropy function. The CrossEntropyLoss function we talked about has the same meaning, and the reader needs to distinguish it by himself. Speaker Earpiece Anti Dust Screen
The speaker earpiece anti dust screen is the dust screen cover on the speaker or handset, so it is also known as the speaker cover. It is generally used in mobile phones, computers, cars, Bluetooth headsets and other sound generating devices. A well-ventilated speaker dust screen ensures that dust and dirt are effectively kept out of the device, ensuring the quality of sound transmission. It also ensures that the device is well ventilated under changing environmental conditions and avoids damage to the housing seal caused by increased internal pressure, which can expose sensitive electronic components to water and dust. Mobile phone speaker mesh and traditional speaker mesh materials are mostly stainless steel, PVC, etc. The metal dust screen also has a strong protective effect and can withstand strong external forces, which is relatively safe. Speaker Anti Dust Screen, Earpiece Dust Screen, Speaker Mesh, Metal Dust Screen, Dust Screen SHAOXING HUALI ELECTRONICS CO., LTD. , https://www.cnsxhuali.com
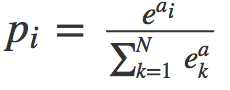

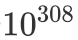 . For exponential functions, this restriction is easily broken, and if this happens, python will return nan.
. For exponential functions, this restriction is easily broken, and if this happens, python will return nan.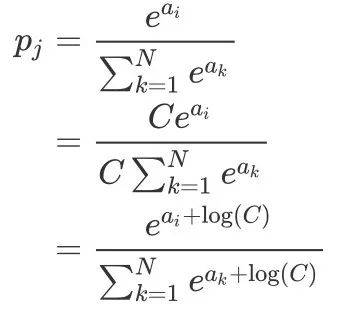
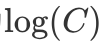 , But generally we will choose
, But generally we will choose 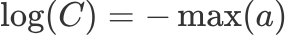 In this way, the originally very large index result becomes 0, avoiding the occurrence of nan.
In this way, the originally very large index result becomes 0, avoiding the occurrence of nan.
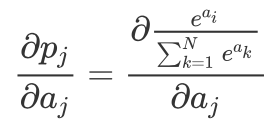
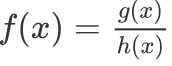 Its derivative is
Its derivative is 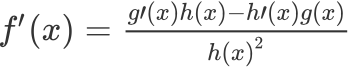
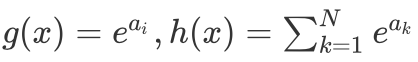
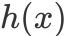 in,
in, Always
Always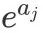 But when
But when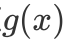 In, if and only if
In, if and only if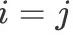 when,
when,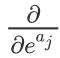 Just for
Just for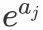 . For the specific process, we look at the following steps:
. For the specific process, we look at the following steps: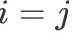
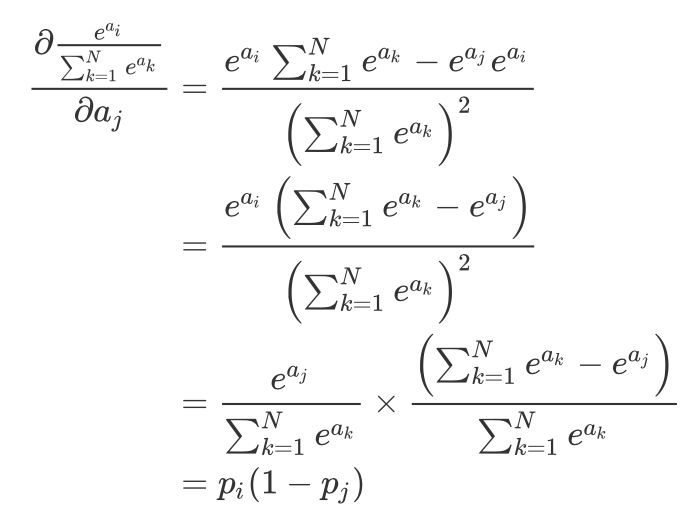
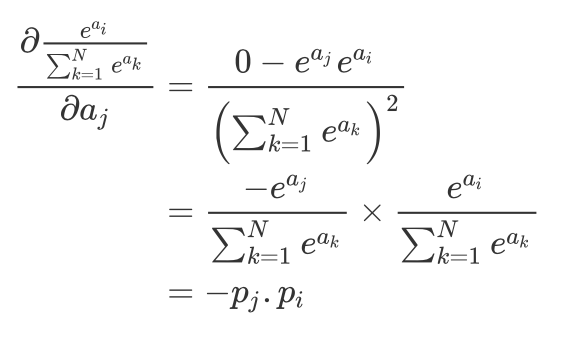
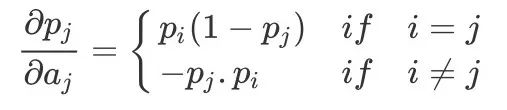
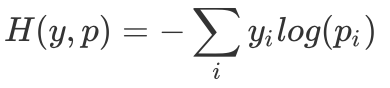

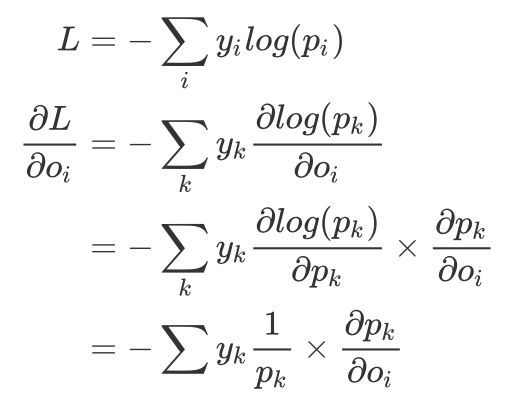
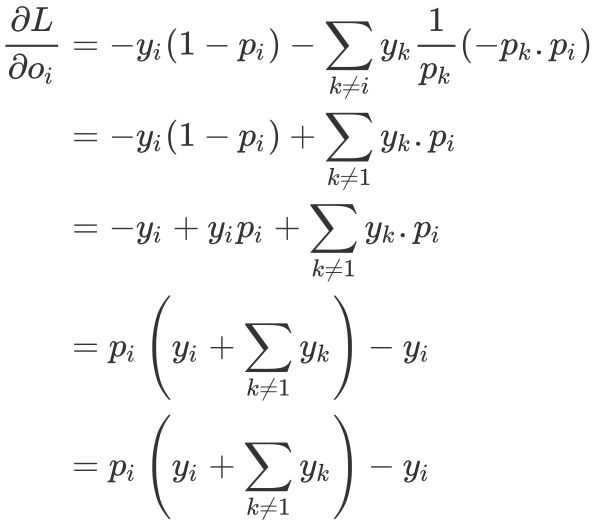
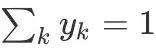
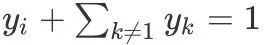 So we can get:
So we can get: 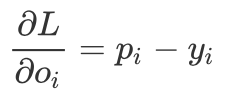

We customize our earpiece dust screen according to the drawings provided by our customers. The raw material we use more often for dust screens is stainless steel. We can achieve a thickness of 0.3mm and are equipped with professional metal etching equipment and exposure development equipment to ensure that our earpiece dust screens have uniformly arranged holes, consistent apertures (200,000 mesh per panel) and a smooth surface without fine holes.